In this post, I’ll summarize a paper by John Houvardas and Efstathios Stamatatos titled N-Gram Feature Selection for Authorship Identification [1]. The topic of the paper is authorship identification, that is, to identify the author of an unlabeled document given a list of possible authors and some sample of each author’s writing. I’ll first motivate the problem of authorship identification, then briefly introduce the relevant statistical methods, and finally, summarize and implement the methods in the paper.
Fig. 1. The authorship identification task.
1. A brief history of stylometry
The Federalist Papers are an important collection of 85 essays written by Hamilton, Madison, and Jay in 1787 and 1788. The essays were published under the alias “Plubious”, and although it became well-known that the three men were involved, the authorship of each paper was kept hidden for over a decade. This was actually in the interest of both Hamilton and Madison; both were politicians who had changed positions on several issues and didn’t want their political opponents to use their own words against them. Days before his death, Hamilton allegedly wrote down who he believed to be the correct author of each essay, claiming over 60 for himself. Madison waited several years before publishing his own list, and in the end, there were 12 essays claimed by both Madison and Hamilton. Details on the controversy are in [2].
Fig. 2. Alexander Hamilton (left) and James Madison (right). (Source: Wikipedia.)
There are a few ways one might go about resolving this dispute. One approach is to analyze the actual content of the text. For example, perhaps an essay draws from a reference with which only Madison was intimately familiar, or maybe an essay is similar to Hamilton’s previous work. This approach was used many times over the next 150 years, but perhaps the final word on the subject was by Adair, who in 1944 concluded that Madison likely wrote all 12 essays.
An alternative approach is to analyze the style of the text. For example, maybe Madison used many more commas than Hamilton. The field of stylometry attempts to statistically quantify these stylistic differences. David Holmes writes the following about stylometry [3]:
At its heart lies an assumption that authors have an unconscious aspect to their style, an aspect which cannot consciously be manipulated but which possesses features which are quantifiable and which may be distinctive.
I think this is a valid assumption. The question is which features best characterize the author’s style and which methods are best to use in the analysis of these features. Let’s go back in time a bit to see how stylometry has developed over the past 150 years.
The physicist Thomas Mendenhall is considered the first to statistically analyze large literary texts. He presented the following idea in an 1887 paper titled The Characteristic Curves of Composition [4]: it is known that each chemical element emits light with a unique distribution of wavelengths when it is heated; perhaps each author has a unique distribution of word lengths in the texts they have written. It’s a cool idea, and I recommend reading his original paper. Mendenhall tallied word lengths by hand for various books, usually in batches of 1000 words or so. Here is Fig. 2 from his paper which shows the characteristic curves for a few excerpts of Oliver Twist.
Fig. 3. Distribution of word lengths in “Oliver Twist”. Each curve is for a different sample of 1000 words. (Source: [4].
Mendenhall showed that these curves reveal similarities between different works by the same author. The use of these statistics for authorship identification was left for future work.
The next significant advance in the statistical analysis of text was made by Zipf in 1932. Zipf found a relationship between an integer \(k\) and the frequency \(f(k)\) of the \(k\)th most frequent word. This is often called a rank-frequency relationship, where \(k\) is the rank. The scaling law can be written as
\[
f(k) \propto k^{-1}.
\tag{1}\]
The idea expressed by this law is that short words are much more frequent than large words. Surprisingly, the law holds up very well, albeit not perfectly, for most texts. Why this is the case is still unknown; a comprehensive review of the current state of the law can be found in [5]. The law also shows up in other situations such as national GDP:
Fig. 4. National GDPs appear to be moving toward the prediction by Zipf’s Law (red line). (Source: [6].)
The success of Zipf’s Law was very encouraging and led to a flurry of new mathematical models. Stylometry reached a landmark case in the 1960s when researchers used the frequency distributions of short function words — words we don’t think about too much like “upon” or “therefore” — to support Adair’s conclusion that Madison wrote the 12 disputed Federalist Papers. At the end of the day, however, models created in the spirit of Zipf’s Law are probably doomed to fail. The “true” underlying model must be very complex due to its dependence on human psychology. There are now many algorithms available which instead build predictive models directly from data, and these can be readily applied to the problem of authorship identification. Here we focus on the use of the Support Vector Machine (SVM).
2. Support Vector Machine (SVM)
I include here the basic idea behind the SVM approach. There are a number of resources that go into the details (such as [7]). I’ll follow the Wikipedia page since it has a nice short summary.
2.1. Maximum margin hyperplane
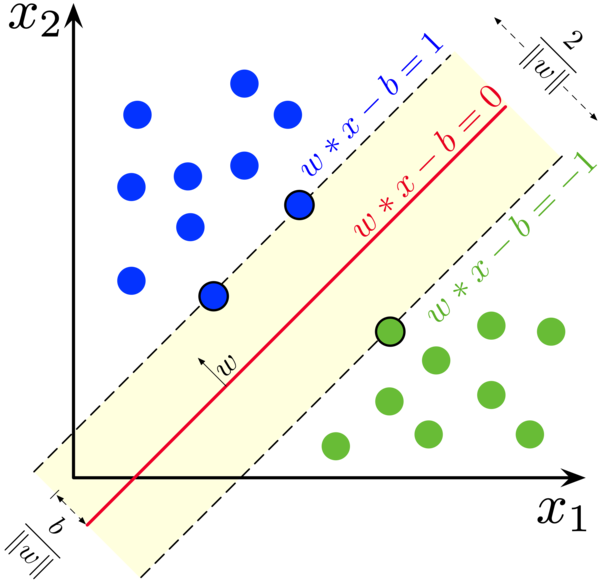
Consider a linear binary classifier, i.e., a plane that splits the data into two classes. The equation for a plane in any number of dimensions is
This plane is called the decision surface; points are assigned to class 1 if \(y(\mathbf{x}) > 0\) or class 2 when \(y(\mathbf{x}) < 0\). Suppose the data is linearly separable (able to be completely split in two) and that we’ve found a plane that correctly splits the data. We could then scale the coordinates such that all points with \(y(\mathbf{x}) \ge 1\) belong to class 1 and all points with \(y(\mathbf{x}) \le -1\) belong to class 2. The separating plane then sits in the middle as in the following figure.
Fig. 5. Maximum margin separating plane. (Source: Wikipedia.)
Notice that the plane could be rotated while still correctly splitting the existing data; the SVM attempts to find the optimal plane by maximizing the orthogonal distance from the decision plane to the closest point. This is known as the margin, and it can be shown that it is inversely proportional to the magnitude of \(\mathbf{w}\). Thus, the SVM tries to minimize \(|\mathbf{w}|^2\) subject to the constraint that all points are correctly categorized. New data is then assigned based on this optimal boundary.
Some datasets won’t be linearly separable, in which case we can add a penalty function in order to minimize the number of miscategorized points. So, for N samples we minimize
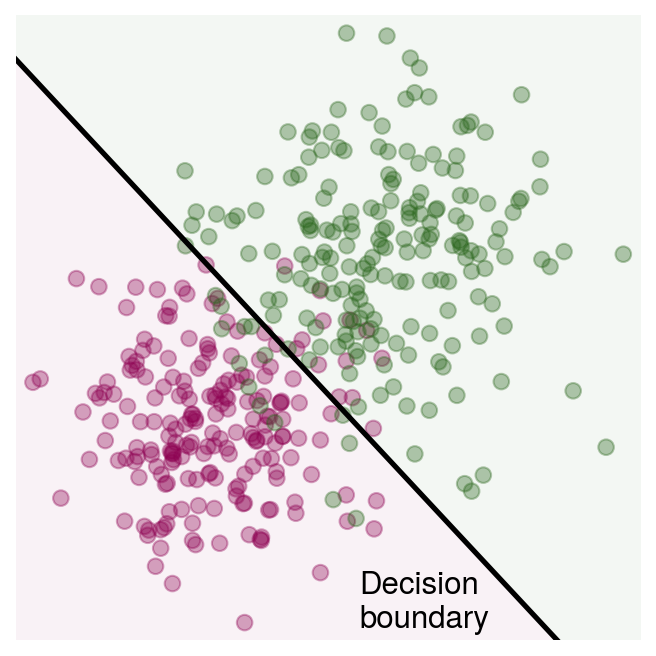
where \(t_i\) is the true class of point \(i\) (\(\pm 1\)) and \(C\) is a positive constant. Correctly classified points don’t contribute anything to the sum since \(t_i y(\mathbf{x}_i)\) will be greater than or equal to one. Let’s try this on non-linearly separable data sampled from two Gaussian distributions in 2D space. The Python package scikit-learn has a user-friendly interface for the SVM implementation in LIBLINEAR which we use here.
Imports
import collectionsimport osimport stringimport matplotlib.pyplot as pltimport numpy as npimport matplotlib.pyplot as pltfrom plotly import graph_objects as goimport plotly.io as pioimport proplot as ppltimport pandas as pdfrom scipy.stats import normimport seaborn as snsimport sklearn.metricsfrom sklearn import svm
Fig. 6. An SVM decision boundary for a two-class data set. Each point is colored by its class.
The points are colored by their true classes, and the background is shaded according to the SVM prediction at each point. It can be important to try at least a few different values of \(C\), which determines the trade-off between correctly classifying all samples and maximizing the margin, and to observe the effect on the accuracy as well as the algorithm convergence. Parameters such as this one which change the algorithm behavior but aren’t optimized by the algorithm itself are commonly known as hyperparameters.
2.2. Kernel trick
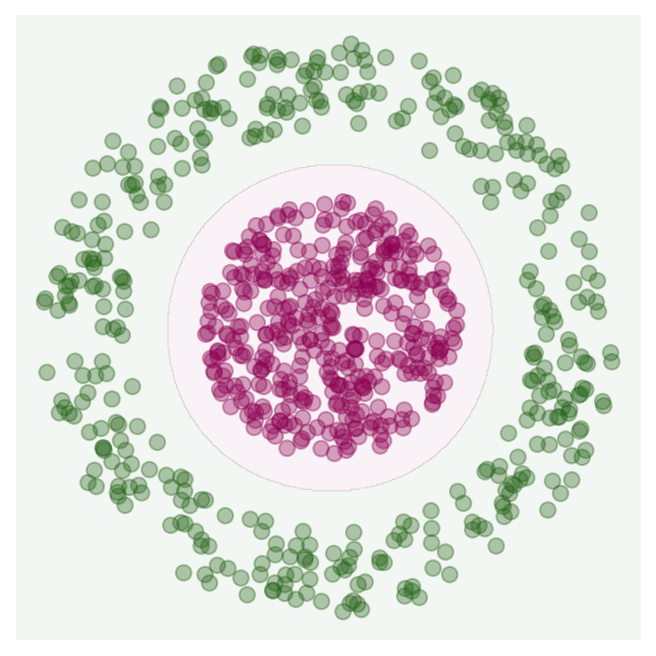
In some cases the linear model is going to be bad; a frequently used example is “target” dataset.
Fig. 7. Two-dimensional data set which no linear model can classify.
A line won’t work; ideally, we would draw a circle around the inner cluster to split the data. The kernel trick can be used to alleviate this problem by performing a transformation to a higher dimensional space in which the data is linearly separable. For example, consider the transformation
Fig. 8. Data after applying the nonlinear transformation in Equation 4. This is an interactive plot.
It’s clear from rotating this plot that the transformed data can be split with a 2D plane. This need not be the transformation used by the SVM — in fact, many transformations can be used — but it demonstrates the idea. The linear boundary in the transformed space can then be transformed into a nonlinear boundary in the original space. One way to plot this boundary is to predict a grid of points, then make a contour plot (the boundary is shown in grey).
There are still several advantages to the linear SVM. First, it is much faster to train, and second, the kernel trick may be unnecessary for high-dimensional data. As we’ll see, text data can involve a large number of very high-dimensional samples, so we’ll be sticking with linear kernels.
2.3. Multi-class SVM
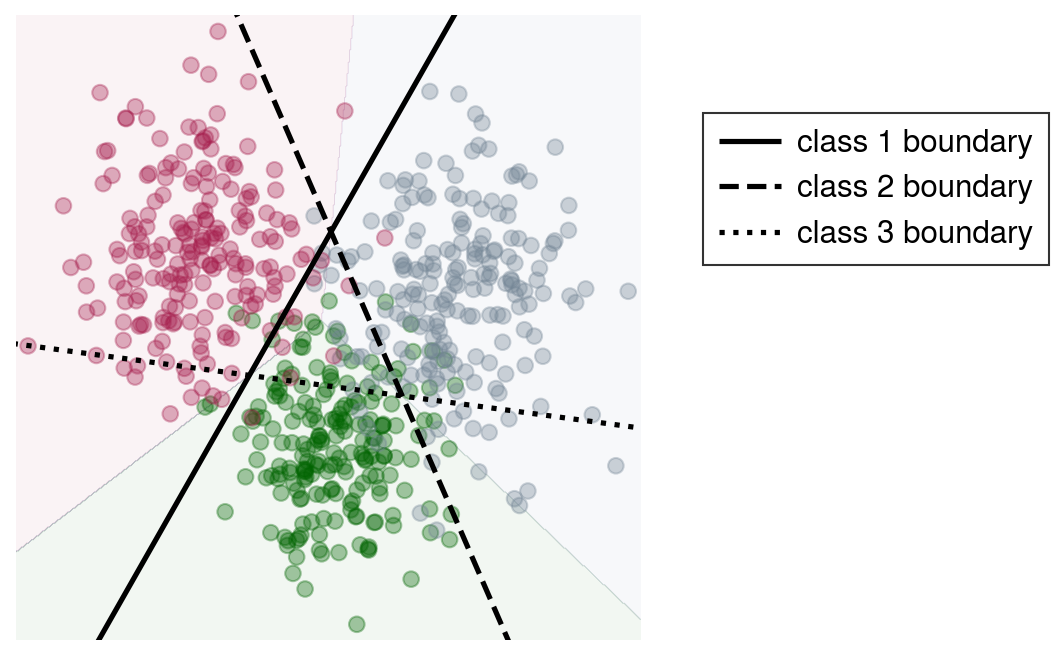
A binary classifier can also be used for multi-class problems. Here we use the one-versus-rest (OVR) approach. Suppose we had \(N\) classes denoted by \(c_1\), \(c_2\) … \(c_N\). In the OVR approach, we train \(N\) different classifiers; the ith classifier \(L_i\) tries to split the data into two parts: \(c_i\) and not \(c_i\). Then we observe a new point and ask each classifier \(L_i\) how confident it is that the point belongs to \(c_i\). The point is assigned to the class with the highest score. We can extend our previous example to three Gaussian distributions to get a sense of how the decision boundaries are formed.
The same idea holds with more classes and dimensions. Notice that there are some regions which are claimed by multiple classifiers, so it’s not a perfect method.
3. N-grams and feature selection methods
As I mentioned in the introduction, the paper I’m following is called N-Gram Feature Selection for Authorship Identification. In short, the paper used n-gram frequencies (defined in a moment) as features in the classification task and developed a new method to select the most significant or “dominant” n-grams. This was tested on a collection of short news articles. Let’s step through their method.
3.1. Data set description
The Reuters Corpus Volume 1 (RCV1) data set is a big collection of news articles labeled by topic. Around 100,000 of these have known authors, and there are around 2000 different authors. A specific topic was chosen, and only authors who wrote at least one article which fell under this topic were considered. From this subset of authors, the top 50 in terms of number of articles written were chosen. 100 articles from each author were selected — 5000 in total — and these were evenly split into a training and testing set. The resulting corpus is a good challenge for authorship identification because the genre is invariant across documents and because the authors write about similar topics. Hopefully this leaves the author’s style as the primary distinguishing factor. The data set can be downloaded here. The files are organized like this:
Fig. 11. Organization of RCV1 data set.
There are plenty of functions available to load the data and to extract features from it, but I’ll do everything manually just for fun. To load the data, let’s first create two lists of strings, texts_train and texts_test, corresponding to the 2500 training and testing documents. The class id and author name for each document are also stored.
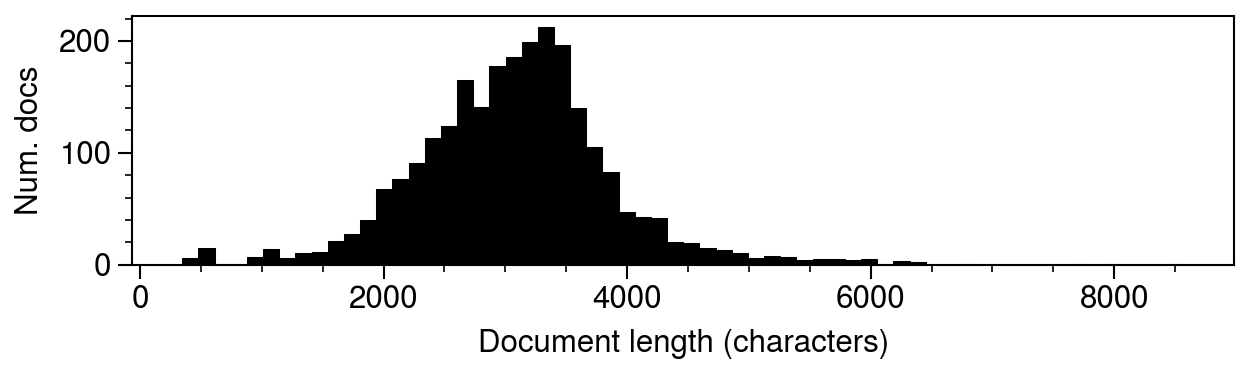
The following histogram shows the distribution of document lengths in the training set; it’s expected that the short average document length will greatly increases the difficulty of the classification task relative to longer works such as books.
Code
word_counts = [len(text) for text in texts_train]fig, ax = pplt.subplots(figsize=(5, 1.5))ax.hist(word_counts, bins='auto', color='black')ax.format(xlabel='Document length (characters)', ylabel='Num. docs')plt.close()
Fig. 11. Distribution of document lengths in training set.
3.2. N-grams
An obvious feature candidate is word frequency; a less obvious one is n-gram frequency. A character n-gram is a string of length n. For example, the 3-grams contained in red_bike! are red, ed_, d_b, *_bi, bik, ike, ke!*. These shorter strings may be useful because they capture different aspects of style such as the use of punctuation or certain prefixes/suffixes. They also remove any ambiguities in word extraction and work for all languages. To use these features in the SVM classifier, we need to create a feature matrix \(X\) where \(X_{ij}\) is the frequency of the jth n-gram in the ith document. Thus, each document is represented as a vector in \(k\) dimensional space, where \(k\) is the number of unique n-grams selected from the training documents. We’ll also normalize each vector so that all points are mapped onto the surface of the \(k\)-dimensional unit sphere while preserving the angles between the vectors; this should help the SVM performance a bit.
def get_ngrams(text, n):return [text[i - n : i] for i inrange(n, len(text) +1)]def get_ngrams_in_range(text, min_n, max_n): ngrams = []for n inrange(min_n, max_n +1): ngrams.extend(get_ngrams(text, n))return ngramsdef sort_by_val(dictionary, max_items=None, reverse=True): n_items =len(dictionary)if max_items isNoneor max_items > n_items: max_items = n_items sorted_key_val_list =sorted(dictionary.items(), key=lambda item: item[1], reverse=reverse)return {k: v for k, v in sorted_key_val_list[:max_items]}class NgramExtractor:def__init__(self, ngram_range=(3, 5)):self.vocab = {}self.set_ngram_range(ngram_range)def set_ngram_range(self, ngram_range):self.min_n, self.max_n = ngram_rangedef build_vocab(self, texts, max_features=None):self.vocab, index = {}, 0for n inrange(self.min_n, self.max_n +1): ngrams = []for text in texts: ngrams.extend(get_ngrams(text, n)) counts = sort_by_val(collections.Counter(ngrams), max_features)for ngram, count in counts.items():self.vocab[ngram] = (index, count) index +=1def create_feature_matrix(self, texts, norm_rows=True): X = np.zeros((len(texts), len(self.vocab)))for text_index, text inenumerate(texts): ngrams = get_ngrams_in_range(text, self.min_n, self.max_n)for ngram, count in collections.Counter(ngrams).items():if ngram inself.vocab: term_index =self.vocab[ngram][0] X[text_index, term_index] = countif norm_rows: X = np.apply_along_axis(lambda row: row / np.linalg.norm(row), 1, X)return X
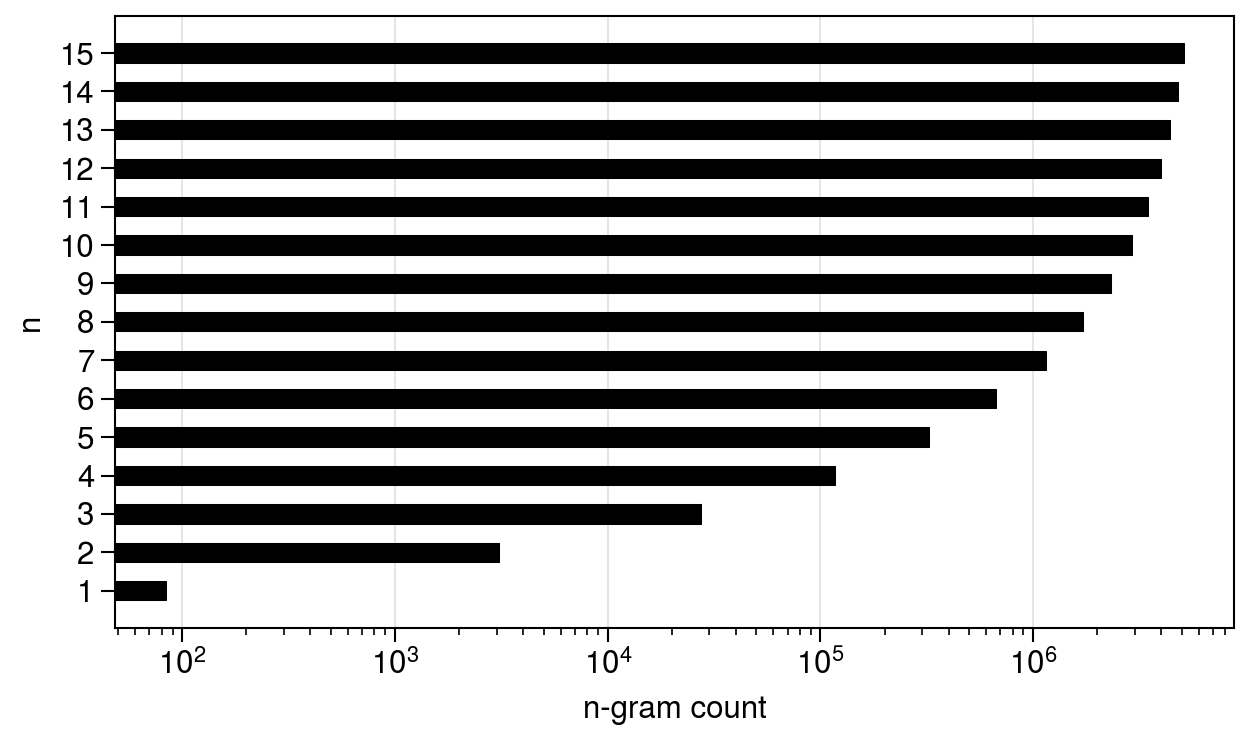
Now we need to decide which value(s) of n to use as features. Let’s look at the distribution of n-grams in the training documents.
extractor = NgramExtractor(ngram_range=(1, 15))extractor.build_vocab(texts_train)len_counts = collections.Counter([len(ngram) for ngram in extractor.vocab])fig, ax = pplt.subplots(figsize=(5, 3))x, y =zip(*len_counts.items())ax.barh(x, y, color='k', alpha=1.0, width=0.5)ax.format(xscale='log', xformatter='log', ylabel='n', xlabel='n-gram count', yticks=x, ytickminor=False)ax.grid(axis='x')plt.close()
fig.save('./_output_n_gram_count.png', dpi=250)
Fig. 12. Distribution of character n-grams in the training text.
The total number of n-grams with 1 \(\le\)n \(\le\) 15 is about 31 million; training a classifier on data with this number of dimensions is probably infeasible, and even more so on a larger data set. Previous studies have had success with fixing the value of n to be either 3, 4, or 5, so the authors chose to restrict their attention to these values. Their new idea was to use all n-grams in the range 3 \(\le\)n \(\le\) 5. This leaves a few hundred thousand features.
The next section will discuss statistical methods to prune the features; for now, though, we’ll implement the simple method of keeping the \(k\) most frequent across all the training documents. As long as this doesn’t affect the accuracy too much, we reap the benefits of a reduction in computational time and the ability to fix the feature space dimensionality for the comparison of different feature types. To see why many low-frequency terms may be unimportant, suppose one of the authors wrote a single article about sharks in the training set. The term “shark” would have a small global frequency and be very useful in the training set since no other writers write about sharks, but it’s probably a good idea to discard it since it is unlikely to appear in the testing set. We must be careful, however, because some low-frequency terms could be important. These are probably terms that an author uses rarely but consistently over time. Maybe they like to use “incredible” as an adjective; the global frequency of “incred” would be much less than, say, “that_”, but it’s valuable because its frequency distribution will likely be the same in future writing. A quick test on our data set shows that \(k\) = 15,000 is a good number. Let’s try this out on the 15,000 most frequent 3-grams.
Here are some of the values in X_train. The columns have been sorted by descending frequency from left to right.
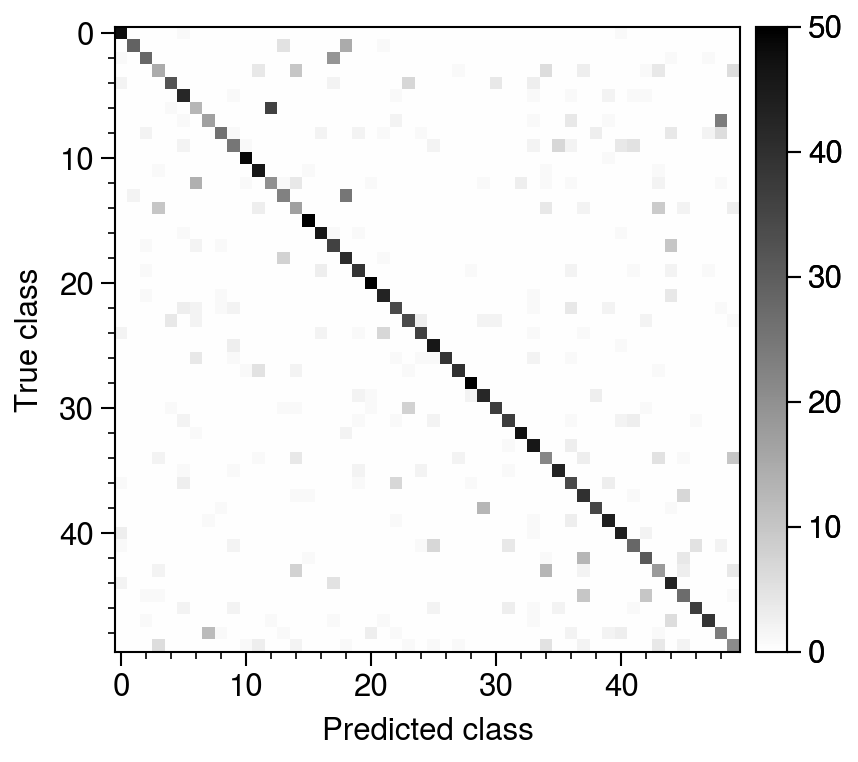
We can now feed this array to the SVM and make predictions on the testing data. I’ll keep the \(C\) parameter fixed at \(C = 1\) in all cases since this is what is done in the paper (I tried a few different values of \(C\) and there wasn’t a large effect on the accuracy). Here is the confusion matrix obtained after training and testing:
Fig. 13. Confusion matrix for linear SVM after training. The total accuracy is 70%.
3.3. Feature selection
In the rest of this post, we’ll study how to use statistical methods to further eliminate features from this initial set of 15,000. This process of selecting features which are “best” in a statistical sense is known as feature selection.
3.3.1. Information gain
A classical statistical measure of feature “goodness” is called information gain (IG). The idea is that knowing whether or not a term t is found in a document of a known class \(c\) gives information about \(c\), and that some terms will contribute more information than others. The information gain can be written as [8]
The probability of choosing term \(t\) out of all terms in the corpus is given by \(p(t)\), and \(p(t) + p(\bar{t}) = 1\). Similarly, \(p(c_i)\) is the probability that a randomly chosen document belongs to class \(c_i\), and \(p(c_i) + p(\bar{c_i}) = 1\). The probability that a document belongs to \(c_i\) given that it contains \(t\) is \(p(c_i | t)\), or \(p(c_i | \bar{t})\) if it doesn’t contain \(t\). The strategy is then to keep the terms with the highest information gain scores.
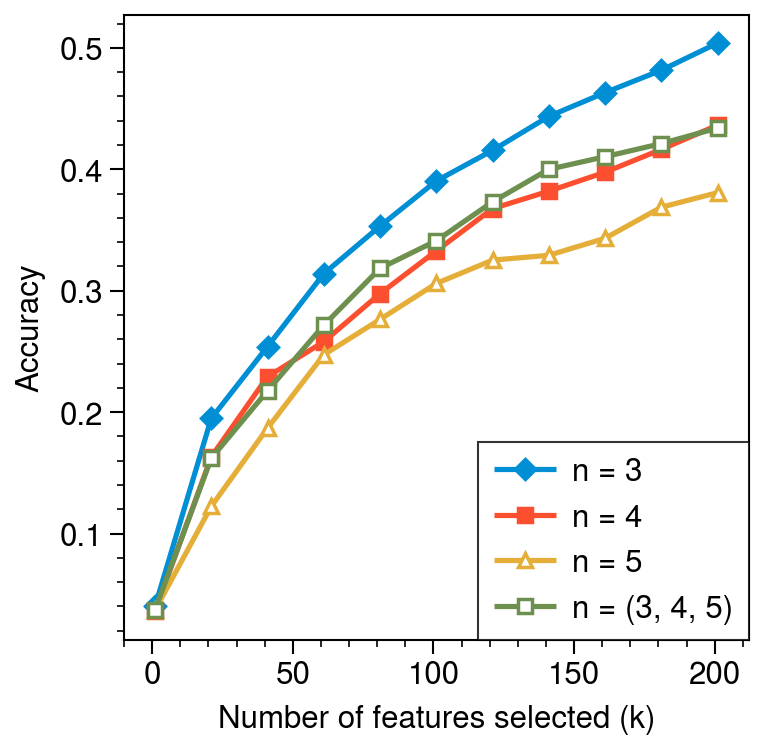
We’ll now compare 4 sets of 15,000 features: 3-grams, 4-grams, 5-grams, and equal parts 3/4/5-grams, each time using IG to select the best \(k\) features and plotting the accuracy vs. \(k\). I’ll start from \(k\) = 1 to 200.
Fig. 14. Information Gain (IG) accuracy vs. number of features (\(k\)) for \(1 \le k \le 200\)
The accuracy at \(k\) = 1 is 0.04, so using the feature with the highest IG score is actually twice as effective as random guessing! By the end of the plot 3-grams and variable length n-grams have taken a clear leaad, with 5-grams in last place. The performance gap between the different n-grams also appears to be growing with \(k\).
The next region we’ll look at is \(200 \le k \le 2000\).
Fig. 15. Information Gain (IG) accuracy vs. number of features (\(k\)) for \(200 \le k \le 2000\)
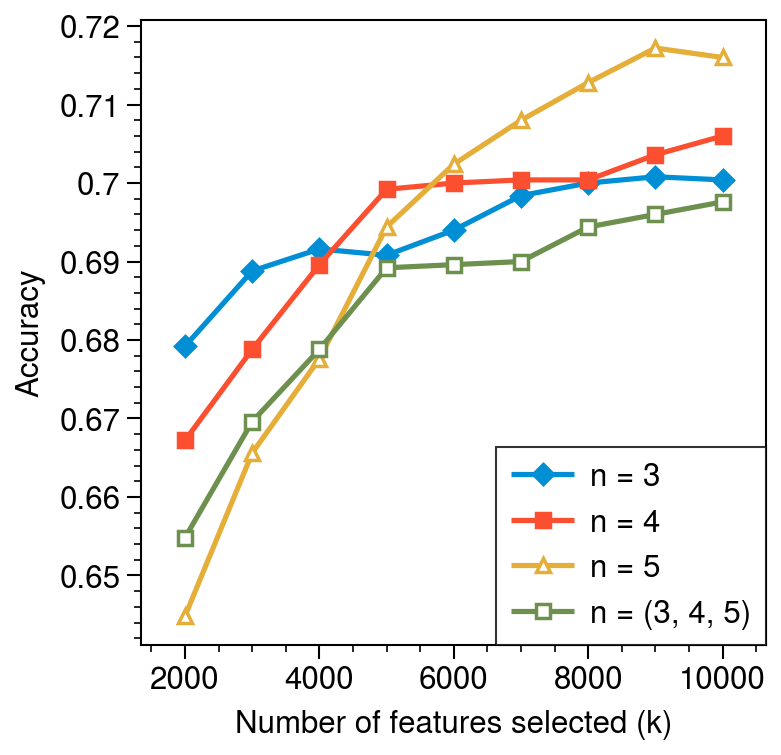
Now the gap is decreasing as we approach an upper performance limit at higher \(k\), especially for 3-grams. We’ll now look at the region which is plotted in the paper: \(2,000 \le k \le 10,000\).
Fig. 16. Information Gain (IG) accuracy vs. number of features (\(k\)) for \(2000 \le k \le 10000\)
I noticed that 5-grams make a big jump from last place to first place. I’m not sure if I have any deep insights into this behavior, but it’s interesting that the best n-gram to choose depends on the number of features selected. Now, I should compare with Fig. 1 from the paper:
Fig. 17. Authorship identification results using information gain for feature selection. (From [1].)
The first difference is the maximum achieved accuracy which is a few percentage points higher. The second difference is that the authors found 3-grams to be worst at low \(k\) and best at high \(k\).and the opposite for 5-grams. I’ll leave this as an open problem.
3.3.2. LocalMaxs algorithm
Let’s look at the top IG scoring n-grams from from the variable-length feature set.
Notice all the variants of the which were included. IG has no way of knowing that these are basically the same. This motivates the definition of something called “glue”. Consider the word bigram Amelia Earhart. These two words are very likely to be found next to each other and could probably be treated as a single multi-word unit; it is as if there is glue holding the two words together. The amount of glue is probably higher than that between, say, window and Earhart. A technique has been developed to quantify this glue and extend its calculation to word n-grams instead of just word bi-grams [9]. The same idea can then be applied to character n-grams.
Let \(g(C)\) be the glue of character n-gram \(C = c_1 \dots c_n\). Assuming we had a way to calculate the glue, how could this concept be used for feature selection? One solution is called the LocalMaxs algorithm. First define an antecedent \(ant(C)\) as an (n-1)-gram which is contained in \(C\), e.g., “string” \(\rightarrow\) “strin” or “tring”. Then define a successor \(succ(C)\) as an (n+1)-gram which contains \(C\), e.g., “string” \(\rightarrow\) “strings” or “astring”. C is selected as a feature if
for all ant(C) and succ(C). Since we’re dealing with 3 \(\le\) n \(\le\) 5, only the latter condition is checked if n = 3, and only the former condition is checked for n = 5. Eq. (6) says that the glue of a selected feature shouldn’t increase by adding a character to or removing a character from the start or end of the n-gram, i.e., the glue is at a local maximum with respect to similar n-grams. Now that the selection criteria are established, we can move on to calculating the glue. Here there are several options, but the one used in the paper is called symmetrical conditional probability (SCP). If we have a bigram \(C = c_1c_2\), then
so SCP is a measure of how likely one character is given the other and vice versa. This formula can be applied to an n-gram \(C = c_1\dots c_n\) by performing a pseudo bigram transformation, which means splitting the n-gram into two parts at a chosen dispersion point; for example, “help” could be split as “h*elp”, “he*lp”, or “hel*p”, where * is the dispersion point. Splitting \(C\) as \(c_1 \dots c_{n-1}\)*\(c_n\) would give
In summary, LocalMaxs loops through every n-gram in the vocabulary, computes the glue as \(g(C) = FairSCP(C)\), and keeps the n-gram if Eq. (6) is satisfied. It differs from IG selection in that the features are not ranked, so the number of selected features is completely determined by the text. The method is implemented below.
def antecedents(ngram):return [ngram[:-1], ngram[1:]]def successors(ngram, characters=None):if characters isNone: characters = string.printable successors = []for character in characters: successors.append(character + ngram) successors.append(ngram + character)return successorsclass LocalMaxsExtractor(NgramExtractor):def__init__(self, ngram_range=(3, 5)):super().__init__(ngram_range)self.counts_list = [] # ith element is dictionary of unique (i+1)-gram counts self.sum_counts_list = [] # ith element is the sum of `counts_list[i].values()`def build_vocab(self, texts, max_features=None):# Count all n-grams with n <= self.max_nself.counts_list, self.sum_counts_list = [], [] candidate_ngrams = {}for n inrange(1, self.max_n +1): ngrams = []for text in texts: ngrams.extend(get_ngrams(text, n)) counts = collections.Counter(ngrams)self.counts_list.append(counts)self.sum_counts_list.append(sum(counts.values()))ifself.min_n <= n <=self.max_n: candidate_ngrams.update(sort_by_val(counts, max_features))self.available_characters =self.counts_list[0].keys() # Select candidate n-grams whose glue is at local maximum self.vocab, index = {}, 0for ngram, count in candidate_ngrams.items():ifself.is_local_max(ngram):self.vocab[ngram] = (index, count) index +=1def is_local_max(self, ngram): glue, n =self.glue(ngram), len(ngram)if n <self.max_n:for succ in successors(ngram, self.available_characters):ifself.glue(succ) >= glue:returnFalseif n >self.min_n:for ant in antecedents(ngram):ifself.glue(ant) > glue:returnFalsereturnTruedef glue(self, ngram): n =len(ngram) P =self.counts_list[n -1].get(ngram, 0) /self.sum_counts_list[n -1]if P ==0:return0.0 Avp =0.0for disp_point inrange(1, n): ngram_l, ngram_r = ngram[:disp_point], ngram[disp_point:] n_l, n_r = disp_point, n - disp_point P_l =self.counts_list[n_l -1].get(ngram_l, 0) /self.sum_counts_list[n_l -1] P_r =self.counts_list[n_r -1].get(ngram_r, 0) /self.sum_counts_list[n_r -1] Avp += P_l * P_r Avp = Avp / (n -1)return P**2/ Avp
The first thing we should do is check the the glue of the derivative n-grams the, *_the*, etc.
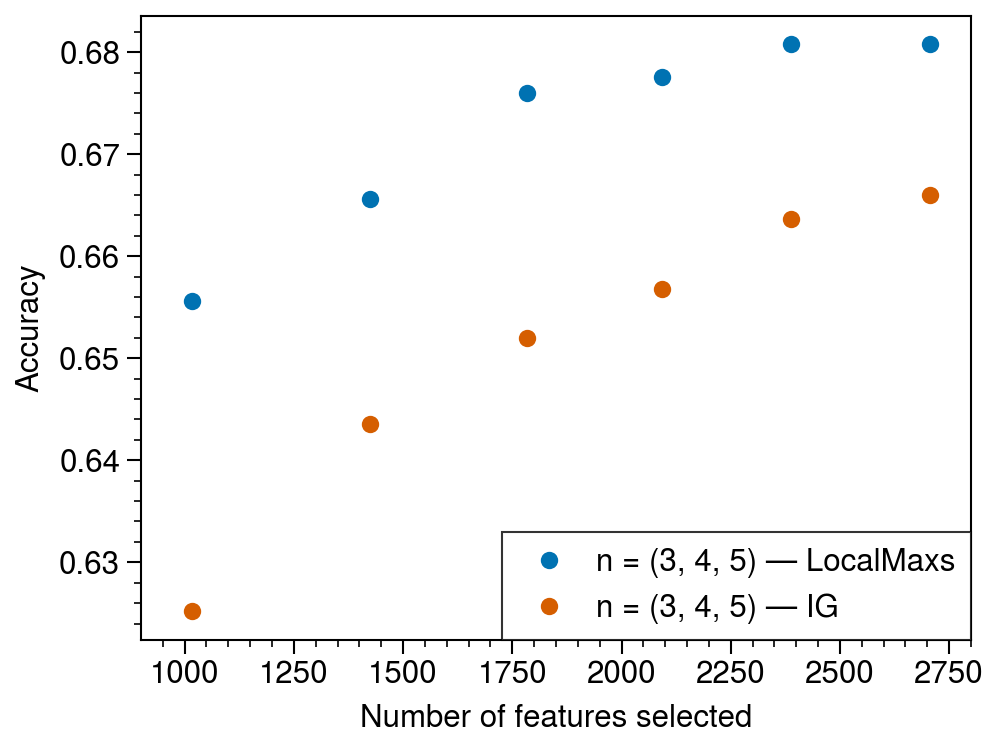
It seems to be working correctly. Now we’d like to compare the performance to IG. There’s no way to directly compare since LocalMaxs doesn’t rank features; however, it’s possible to vary the size of the initial set of features from which LocalMaxs makes its selections. Below, this initial size is varied from 3,000 to 24,000 using equal parts 3/4/5 grams as features.
Fig. 18. IG vs. LocalMaxs feature selection for 3/4/5-grams.
As you can see, LocalMaxs achieves a higher accuracy with the same number of features. The neat thing is that the vocabularies are totally different; for example, at the last data point, only about 15% of the n-grams are found in both sets! Let’s count the number of related n-grams in the two sets, where x is related to y if x is an antecedent or successor of y.
Code
def count_related(ngrams): count =0for n1 in ngrams:for n2 in ngrams:if n1 != n2 and n1 in n2: count +=1breakreturn countlm_ngrams =list(lm_vocabs[-1])vocab_size =len(lm_ngrams)ig_vocab =list(ig_extractor.vocab)ig_ngrams = [ig_vocab[i] for i in ig_selector.idx[:vocab_size]]shared =len([ig_ngram for ig_ngram in ig_ngrams if ig_ngram in lm_ngrams])print('Vocab size: {}'.format(vocab_size))print('n-grams selected by both IG and LM: {}'.format(shared))print('IG related n-grams: {}'.format(count_related(ig_ngrams)))print('LM related n-grams: {}'.format(count_related(lm_ngrams)))
As mentioned earlier, IG selects many related terms such as the and the_. The LocalMaxs vocabulary is much “richer”, as the authors put it. Here is the corresponding figure from the paper (ignore the white squares):
Results of the proposed method using only variable-length n-grams and variable-length n-grams plus words longer than 5 characters. (Source: [1].)
For some reason, their implementation extracted way more features than mine did. I don’t have access to the author’s code, and I couldn’t find any implementation of LocalMaxs online, so it’s hard for me to say what’s happening. At least my implementation exhibits some expected behavior (less related terms, better performance at lower feature numbers).
4. Conclusion
In the future, I may apply these methods to my own data set; I’m particularly interested in what would happen with Chinese characters. A different problem I’d like to examine is that of artist identification; the problem would be to match a collection of paintings with their painters. The Web Gallery of Art is a database I found after a quick search, and I’m sure there are others. This would give me the chance to learn about image classification.
References
[1]
J. Houvardas and E. Stamatatos, N-Gram Feature Selection for Authorship Identification, in Artificial Intelligence: Methodology, Systems, and Applications, edited by J. Euzenat and J. Domingue (Springer Berlin Heidelberg, Berlin, Heidelberg, 2006), pp. 77–86.
[2]
A. Douglass, The Authorship of the Disputed Federalist Papers, The William and Mary Quarterly 1, 97 (1944).
[3]
D. Holmes, The Evolution of Stylometry in Humanities Scholarship, Literary and Linguistic Computing 13, 111 (1998).


![Fig. 3. Distribution of word lengths in “Oliver Twist”. Each curve is for a different sample of 1000 words. (Source: [4].](Mendenhall_Fig2.png)
![Fig. 4. National GDPs appear to be moving toward the prediction by Zipf’s Law (red line). (Source: [6].)](Cristelli_Fig1_big.png)


![Fig. 17. Authorship identification results using information gain for feature selection. (From [1].)](stamatatos_fig1.png)
![Results of the proposed method using only variable-length n-grams and variable-length n-grams plus words longer than 5 characters. (Source: [1].)](stamatatos_fig2.png)